
기업 전산화를 이끈 구조적 방법론(Structured Methodology)은 Peter Chen 박사가 주창한 엔티티 관계 다이어그램(Entity-Relationship Diagram)을 통해 데이터 모델을 완성했다. 초기 Chen 박사의 ER 다이어그램에서는 엔티티는 직사각형으로 표시하고 두 엔티티의 관계는 실선과 마름모꼴 사각형으로 표시했다. 이 간단한 표기법(Notation)은 업무 전산화를 위한 사용요구사항(User Requirement)을 제시하는 현업실무담당자와 전산시스템을 설계하는 전산 기술자와의 의사소통을 원활하게 하기 위함이었다. 전산화 시대에서부터 데이터 모델의 데이터는 직사각형으로 표현하고 활동 모델의 프로세스는 버블로 표현하며 관계는 실선으로 은유적(metaphorical) 표기법이 정착했다.
방법론에서 표기법이 가지는 의미는 현업 실무담당자와 시스템 개발 기술자와의 원활한 의사소통뿐만 아니라, 생산성을 높이는 CASE(Computer Aided Software Engineering) 툴과 같은 지원 도구를 개발하는 계기가 되었다. 기업 정보화를 실현하기 위해 출발한 Clive Finkelstein과 James Martin 박사의 정보공학(Information Engineering) 방법론은 CASE 툴을 기반으로 엔터프라이즈 차원의 통합 데이터 모델을 완성하게 해주었다. CASE 툴에 힘 입어 성장한 Ellis-Barker 표기법은 데이터 모델을 바로 데이터베이스 스키마로 변환할 수 있는 메카니즘을 가지고 있었다.
간단명료한 표기법으로 복잡한 기업 데이터를 표현하는 ER 다이어그램은 엔티티간의 관계를 표현하는 다양한 방법에 따라 구분한다. 두 엔티티간의 관계수(Cardinality) 및 관계조건인 필수선택성(Mandatory-Optionality)에 대한 표현이 독특하다. 정보공학 표기법은 Ellis-Barker 표기법과 같이 복수 관계수를 ‘까마귀 발’로 표현하지만, 관계조건의 선택성은 동그라미와 점선으로 표시하여 차이를 가진다. 데이터 모델링 방법이 변화하며 엔티티 유형을 서브-유형으로 보다 명확하게 정의하고 엔티티간 배타적(Exclusive) 관계도 표현할 수 있게 되었다.
객체지향(Object-Oriented) 일반화(Generalization)/특수화(Specialization) 개념을 수용한 IDEF1X(주1)는 의미적(Semantic) 데이터 모델을 위해 개발되었다. IDE1X는 미국 공군 ICAM(Integrated Computer-Aided Manufacturing) 프로그램을 통해 시맨틱 데이터 모델을 개발하기 위한 방법론이다. 정보공학 데이터 모델링 방법에서 수용한 식별-관계(Identifying Relationship)은 IDEF1X에서도 수용하고 있다. 독립적인 엔티티 유형은 직사각형으로 표시하고 특수화(Specialization)로 ‘is-a’나 ‘has-a’관계인 엔티티 유형은 모서리가 각이 지지않은 사각형을 사용하고 배타적 관계를 표현하는 방법은 포함하고 있지 않다. 한때 우리나라에 IDEF1X 표기법을 따르는 데이터 모델링 툴이 보급되었지만, 표기법이 익숙하지 않아 정보공학 표기법을 함께 선택하도록 바뀌었다.
데이터 모델링 표기법은 방법론의 개념에 대한 변화를 수용해 나가지만, 지원 툴에 종속적인 영향을 많이 받게 된다. 모든 방법론과 지원 도구에서 수용하지 못하고 있는 표기는 시간에 따라 이전(transferable)하는 엔티티 유형간의 관계이다. 기업의 복잡한 데이터를 보다 명확하게 모델링할 수 있는 방법으로 객체지향(Object-oriented) 패러다임에 기반한 UML(Unified Modeling Language)의 클래스 다이어그램(Class Diagram)이다. 클래스 다이어그램에 대한 개념과 표기법은 IDEF1X와 유사하지만, 객체지향 분석 및 설계 방법론이 가지는 식별자(Identifier)를 정의하는 메카니즘이 다르다.
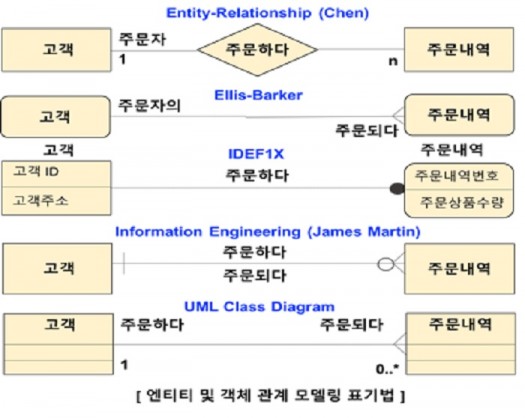
위에서 설명한 데이터 모델을 표현하는 기법은 데이터를 인식하기 시작한 전산화 시대에서 태동하여 정보화 시대를 넘어 지식화 시대로 접어드는 현재까지 기업의 데이터를 발견하고 정의하여 모델을 완성한다. 현재 사용하는 데이터 모델링 기법과 지원하는 도구가 완벽하다 할 수 없고 변화를 지속적으로 수용하여 기업의 모든 형태(구조적, 반구조적, 비구조적) 데이터를 하나의 표기법을 통해 모델을 완성하려고 노력한다. 정부기관과 기업은 자신의 문화에 익숙한 데이터 모델링 방법을 선택하여 전사적 차원의 통합 데이터 모델을 정립하고 그 모델을 기반으로 통합 데이터베이스를 구축해야 한다.
결론적으로 정부기관과 기업이 4차 산업혁명을 대비하여 데이터 매니먼트 체계를 갖추기 위해서는 선정한 데이터 모델링 기법을 통해 전사 통합 데이터 모델을 완성해야 한다. 그리고 데이터 모델링 기법의 메타-모델을 기반으로 메타-데이터 리포지토리(Meta-data Repository)를 구축하여 엔터프라이즈 지식체계를 갖추어야 한다. 엔터프라이즈의 혁신은 비즈니스 아키텍처를 실현하기 위한 집중적인 비즈니스 활동과 통합 데이터를 통해 이루어진다.
주1) 미국 공군 ICAM(Integrated Computer-Aided Manufacturing) 프로그램을 통해 시맨틱 데이터 모델을 개발하기 위한 방법론 임. ICAM Definition language(IDEF)는 IDEF0(function Model), IDEF1(Information Model), IDEF2(dynamics model) 등으로 구성됨.
이재관 objectjk@gmail.com 필자는 30년전, 중소기업 전산화를 위해 프로그래머로부터 출발하여 광양제철소 생산공정 진행을 위한 데이터베이스의 데이터 정합성을 관리하며 데이터 품질 분야에 첫 발을 내디뎠다. 제임스 마틴 박사의 정보공학방법론에 매료되어 기업과 정부기관의 정보전략기획 및 정보시스템 구축 프로젝트를 위한 컨설팅을 수행하였다. 최근 2년전에 DAMA International의 Korea Chapter를 설립하여 엔터프라이즈 데이터 매니지먼트(eDM) 프레임워크를 연구하며 세계의 데이터 매니지먼트 그룹들과의 연계와 지식을 보급하는 활동을 전개해 나가고 있다.
관련기사
- [이재관의 엔터프라이즈 데이터 아키텍처 꿰뚫기] 비즈니스 아키텍처 구현을 위한 ‘엔터프라이즈 통합’ 데이터 아키텍처
- [이재관의 엔터프라이즈 데이터 아키텍처 꿰뚫기] 엔터프라이즈 데이터 아키텍처와 보안, 프라이버시
- [이재관의 엔터프라이즈 데이터 아키텍처 꿰뚫기] 엔터프라이즈 빅데이터를 위한 아키텍처
- [이재관의 엔터프라이즈 데이터 아키텍처 꿰뚫기] 엔터프라이즈 데이터 아키텍처, 누가 만들고 관리해야 할까?
- [이재관의 통합 데이터 모델링 이해] 정보화를 위한 전사 통합 데이터 모델링이란?
- [이재관의 통합 데이터 모델링 이해] 통합 데이터 모델링 방법론과 메타-모델
- [이재관의 데이터 지식여행] 데이터로 고객 마음 사로잡기
- [이재관의 데이터 지식여행] 개인 데이터를 정보로 업그레이드하기
- [이재관의 통합 데이터 모델링 이해] 전사 통합 데이터 스튜와드쉽과 모델 관리
- [이재관의 통합 데이터 모델링 이해] 래거시 및 빅데이터를 수용한 통합 데이터 리모델링
- [이재관의 통합 데이터 모델링 이해] 기업 정보를 얻기 위한 다차원 데이터 모델링